离线数仓与实时数仓 软件开发中的核心差异与应用场景
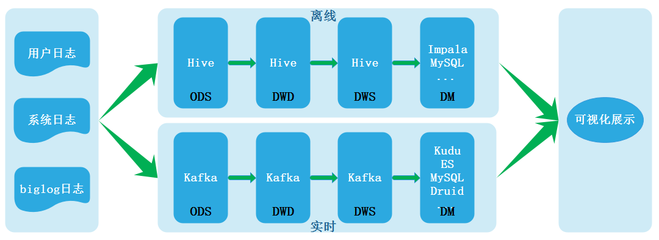
在当今数据驱动的软件开发领域,数据仓库(Data Warehouse)作为企业数据管理的核心基础设施,扮演着至关重要的角色。根据数据处理和响应的时效性,数据仓库主要分为离线数仓(Offline Data Warehouse)和实时数仓(Real-time Data Warehouse)两种类型。它们在架构设计、技术选型、应用场景及开发流程上存在显著差异。以下将详细探讨离线数仓与实时数仓在软件开发中的区别。
一、数据处理时效性的差异
离线数仓通常采用批处理(Batch Processing)方式,数据采集、清洗、转换和加载(ETL过程)在固定的时间间隔内完成,例如每天、每周或每月。这种模式适用于对实时性要求不高的场景,如历史数据分析、报表生成和趋势预测。开发离线数仓时,常用技术包括Hadoop、Hive、Spark等,这些工具能够高效处理大规模数据,但延迟较高,数据从产生到可用可能需要数小时甚至更长时间。
实时数仓则强调低延迟和高吞吐,数据从源头到分析结果的流转几乎是实时的,通常在秒级或分钟级内完成。它采用流处理(Stream Processing)技术,适用于需要即时响应的应用,如金融风控、实时推荐系统和物联网监控。在软件开发中,实时数仓常依赖Kafka、Flink、Storm等框架,这些工具支持事件驱动架构,确保数据持续流入和处理。
二、架构设计与技术栈的对比
离线数仓的架构通常以数据湖(Data Lake)或分层结构(如ODS、DWD、DWS层)为基础,数据流向呈周期性。开发过程中,重点在于优化批处理作业的性能和资源管理,例如使用Spark进行分布式计算,或通过Hive进行SQL查询优化。这种架构简化了数据一致性管理,但缺乏实时性。
实时数仓的架构则更复杂,往往结合了流处理引擎和消息队列。数据从源端(如数据库日志或传感器)通过Kafka等消息中间件实时流入,再由Flink或Spark Streaming进行处理和存储。软件开发时,需考虑状态管理、容错机制和水平扩展,以应对高并发和数据丢失风险。实时数仓常与OLAP数据库(如ClickHouse或Druid)集成,以支持快速查询。
三、应用场景与业务需求的适配
离线数仓在软件开发中主要用于离线分析和决策支持。例如,电商平台可使用离线数仓分析用户历史购买行为,生成月度销售报表;或企业利用它进行数据挖掘,优化长期战略。开发这类系统时,重点在于数据建模、ETL流程设计和性能调优,而对实时性要求较低。
实时数仓则适用于对时效性敏感的场景。例如,在金融领域,实时数仓可监控交易数据,快速检测欺诈行为;在在线广告中,它能根据用户实时行为调整推荐内容。软件开发中,实时数仓的挑战在于保证数据准确性和系统稳定性,需要精细的监控和告警机制。
四、开发流程与维护成本的考量
从软件开发流程来看,离线数仓的开发相对成熟和标准化。团队可以遵循传统的ETL管道设计,使用调度工具(如Airflow)自动化任务,并通过数据质量检查确保可靠性。维护成本较低,因为批处理作业在非高峰时段运行,资源需求可预测。
实时数仓的开发则更具挑战性,需要敏捷的迭代和持续集成。开发团队必须处理流数据的无序性和重复问题,并实现高效的资源调度。维护成本较高,因为系统需7x24小时运行,且对网络延迟和硬件故障更敏感。因此,实时数仓的软件开发往往需要更多的测试和运维投入。
五、未来趋势与融合方向
随着大数据技术的发展,离线数仓和实时数仓的界限正在模糊。Lambda架构和Kappa架构的出现,允许企业在同一系统中结合批处理和流处理,从而平衡实时性与成本。在软件开发中,开发者应评估业务需求,选择或融合合适的方案。例如,采用数据湖仓一体化架构,既能处理历史数据,又能支持实时查询。
离线数仓和实时数仓在软件开发中各有优劣。离线数仓适合对延迟不敏感的分析任务,开发注重稳定性和可扩展性;实时数仓则满足即时决策需求,开发强调低延迟和高可用性。选择哪种方案,需根据具体业务场景、资源约束和团队能力综合权衡。在日益复杂的数据环境中,掌握两者的差异,将有助于开发更高效、可靠的数据驱动应用。
如若转载,请注明出处:http://www.tobeonetop.com/product/9.html
更新时间:2026-06-18 15:53:38









