在线监测超标异常数据的识别、处理与优化策略
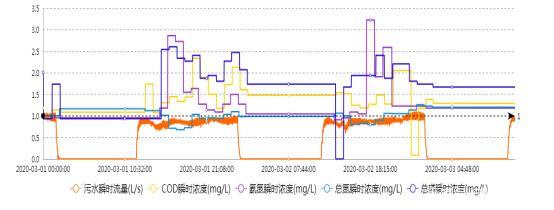
在线监测系统在环境、工业、医疗、能源等诸多领域扮演着至关重要的角色,其产生的连续数据流是进行实时监控、预警和决策的基础。监测数据中不可避免地会出现超标值和各类异常值。这些数据若处理不当,可能导致误报警、掩盖真实问题或引发错误的管控措施。因此,建立一套科学、系统、自动化的超标异常数据处理流程,是确保数据质量、提升监测效能的核心环节。
一、 异常数据的识别与分类
在着手处理之前,首先需精准识别何为“异常”。通常,异常数据可分为以下几类:
- 技术性异常(故障异常):由监测设备故障、校准漂移、采样系统堵塞、通信中断、电源波动等硬件或传输问题导致。这类数据通常表现为突变的极值(如突变为0或满量程值)、长时间无变化、或完全脱离物理可能的范围。
- 过程性异常(真实超标):由于被监测对象本身的过程发生剧烈变化所致,例如污染物排放浓度骤然升高、设备运行参数超出安全阈值、患者生理指标急剧恶化等。这是监测系统需要捕捉和报警的“真异常”。
- 干扰性异常:由偶然的外部干扰引起,如临时性的现场扰动、气候条件骤变(强风、暴雨对空气质量监测的影响)、或样本受到偶然污染。其特点是短暂出现后可能恢复正常。
识别方法包括:基于统计的控制图法(如Shewhart控制图)、基于阈值的规则判断(超过国标、行标或设定限值)、基于时间序列的模型预测(如ARIMA模型,偏差超出置信区间)、以及日益普及的机器学习算法(如孤立森林、自编码器)进行无监督异常检测。
二、 系统化的处理流程与策略
处理超标异常数据应遵循“识别-标记-调查-处理-记录”的闭环流程。
第一步:自动标记与初步预警
监测系统应设置多级预警阈值。一旦数据触发规则,系统自动将其标记为“疑似异常”,并根据超限幅度和持续时间,启动不同级别的预警(如提醒、警告、严重报警),同时通知相关人员。原始数据必须被完整保存,不可直接删除。
第二步:人工/自动核实与原因调查
收到预警后,操作人员或自动诊断系统需立即进行核实:
- 远程核查:查看同一监测点其他关联参数是否同步异常,检查设备状态日志(如校准记录、故障代码、通信信号强度)。
- 现场核查:若远程无法判断,需派员进行现场检查,包括设备运行状态、采样管路、试剂、标准气体、环境条件等。
- 过程关联分析:结合生产台账、运维记录、气象数据等,分析异常是否与已知的生产工艺变化、维护活动或外部事件相关联。
第三步:数据判定与分类处理
根据调查结果,对异常数据进行判定并采取相应处理措施:
- 确认为技术性异常:数据无效。应在数据库中将该时段数据明确标记为“无效数据”,并注明原因(如“设备故障”、“校准期间”)。在后续的数据统计、报告编制中,这部分数据应被排除。必须立即启动维修维护程序,确保设备恢复正常。
- 确认为过程性异常(真实超标):数据有效且至关重要。系统应升级报警,启动应急预案。该数据必须保留,并作为考核、溯源、处罚或诊断的关键依据。需深入分析超标原因,并评估其持续性和影响范围。
- 确认为干扰性异常:数据代表性存疑。可标记为“可疑数据”或“无效数据”。若异常短暂且原因明确,有时可根据前后有效数据,采用谨慎的方法进行插值或平滑处理(仅用于趋势展示,不可用于合规性判断),并需详细备注说明。
第四步:数据修正与填补(谨慎使用)
对于被判定无效的数据缺口,在特定分析需求下(如趋势连续展示),可采用数据填补方法,但必须透明化:
- 向前/向后填充:仅适用于极短时间的中断。
- 线性插值:适用于变化平缓的参数。
- 基于模型的预测:利用历史数据或关联参数建立模型进行估算。
关键原则:任何数据填补都不能用于法律规定的达标判定、排放量精确计算或关键决策。原始异常数据和填补数据、填补方法必须在报告中清晰区分和说明。
第五步:记录与归档
所有异常事件、调查过程、判定依据、处理措施、参与人员、修复结果等,都必须形成完整的电子日志或报告,与原始数据关联保存。这是质量体系审计、责任追溯和经验积累的重要资产。
三、 预防性优化措施
最好的处理是预防。为减少异常数据发生,应采取以下优化措施:
- 强化设备运维管理:制定并严格执行定期校准、预防性维护、备品备件更换计划。采用设备健康度监控技术。
- 完善数据质量控制系统:在数据采集端部署多层数据校验规则(合理性检验、一致性检验、趋势性检验),实现初步的实时“过滤”。
- 提升系统智能水平:利用大数据和AI技术,构建更精准的设备故障预测模型和异常诊断专家系统,实现从“事后处理”到“事前预警”和“智能诊断”的转变。
- 健全制度与培训:建立明确的数据质量管理程序和岗位职责,定期对运维和数据分析人员进行培训,提升其异常识别与应急处理能力。
###
处理在线监测超标异常数据,绝非简单的“删除”或“忽略”,而是一个融合技术、管理和经验的系统性工程。其核心目标是在保障数据真实性与完整性的前提下,有效甄别噪声与信号,确保监测结论的准确可靠,从而为过程优化、风险防控和科学决策提供坚实的数据基石。建立透明、规范、可追溯的数据处理流程,是每一个依赖在线监测的领域必须夯实的质量管理基础。
如若转载,请注明出处:http://www.tobeonetop.com/product/55.html
更新时间:2026-06-18 14:05:28