科技数据收集与处理 从海量信息到精准洞察

在当今以数据驱动的科技时代,数据已成为与土地、劳动力、资本和技术并列的关键生产要素。科技数据的收集与处理,是挖掘其价值、驱动创新的核心环节。本文将探讨这一过程的关键步骤与意义。
一、数据收集:构建价值的基石
数据收集是数据处理流程的起点,其质量直接决定后续分析的深度与广度。科技领域的数据收集主要包含以下几个层面:
- 来源多样化:数据可来自物联网传感器、网络日志、移动应用、科学实验、社交媒体、公共数据库及商业交易等。例如,智能工厂的传感器实时采集设备运行参数,天文望远镜持续捕捉深空影像数据。
- 类型复杂化:除了传统的结构化数据(如数据库表格),更多的是半结构化(如JSON、XML文件)和非结构化数据(如文本、图像、音频、视频)。例如,一篇科研论文的文本、其中包含的图表以及相关的实验视频,共同构成了一个多模态数据集。
- 实时性要求高:许多应用场景,如自动驾驶、金融风控和工业监控,要求数据能够被近乎实时地收集和响应,这对采集系统的吞吐量与延迟提出了严峻挑战。
二、数据处理:从原始信息到可用知识
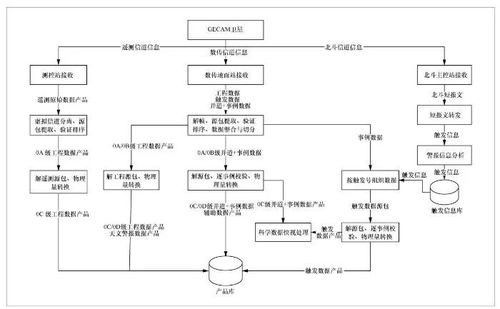
原始数据通常存在噪声、不一致、不完整等问题,无法直接用于分析。数据处理正是为了将“原始矿石”冶炼成“高纯金属”,其核心流程包括:
- 数据清洗与预处理:这是至关重要的一步,涉及处理缺失值、纠正错误、识别并移除异常值、统一数据格式与单位等。例如,在生物信息学中,需要对基因测序产生的海量原始读数进行质量控制和纠错。
- 数据整合与转换:将来自不同源头、格式各异的数据进行整合,消除冗余与矛盾,并转换为适合分析的统一形式。这可能涉及数据融合、归一化、聚合以及特征工程(即从原始数据中构建更有意义的特征变量)。
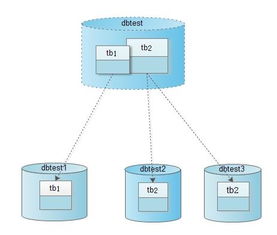
- 数据存储与管理:根据数据的结构、规模和访问模式,选择合适的存储方案,如关系型数据库、NoSQL数据库、数据湖或数据仓库。高效的数据管理系统是确保数据可用性、安全性与完整性的基础。
- 分析与建模:利用统计分析、机器学习、数据挖掘等技术,从处理好的数据中发现模式、趋势、关联和洞见。例如,通过处理用户行为数据,科技公司可以构建推荐模型;通过分析天文数据,科学家可能发现新的天体现象。
三、关键技术与挑战
科技数据的处理依赖于一系列前沿技术:
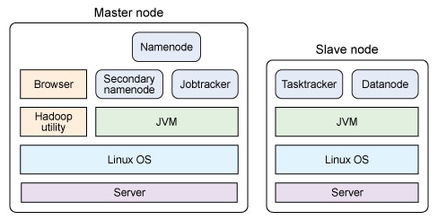
- 分布式计算框架:如Apache Hadoop、Spark,用于处理PB乃至EB级别的海量数据。
- 流处理技术:如Apache Flink、Kafka Streams,满足实时数据处理需求。
- 云平台与容器化:提供了弹性、可扩展的计算与存储资源。
- 人工智能与机器学习:不仅是数据分析的工具,其自身训练也产生了巨量数据,形成了数据收集与处理的闭环。
面临的挑战同样突出:数据隐私与安全(如GDPR等法规)、数据质量保障、处理系统的能耗问题、以及跨领域、跨模态数据融合的复杂性。
四、价值与展望
高效的数据收集与处理,最终将数据转化为可行动的见解与决策支持,驱动科技创新:
- 加速科学研究:如在高能物理、气候模拟等领域,实现从数据到发现的快速循环。
- 赋能产业发展:优化生产流程、实现预测性维护、创造个性化产品与服务。
- 提升社会治理:在智慧城市、公共健康等领域实现更精细化的管理。
随着边缘计算、人工智能原生数据库、隐私计算等技术的发展,数据收集与处理的边界将进一步延伸,过程将更加智能化、自动化与安全化,持续释放数据作为核心生产要素的巨大潜能。
如若转载,请注明出处:http://www.tobeonetop.com/product/51.html
更新时间:2026-06-18 08:58:04