11步构建完整产品数据运营体系 数据处理篇
在数据驱动的时代,高效、准确的数据处理是产品数据运营体系的核心支柱。它不仅是数据采集与数据分析之间的桥梁,更是确保决策依据可靠性的关键环节。下面,我们将通过11个具体步骤,系统阐述如何构建一个完整、高效的数据处理体系。
步骤1:明确数据处理目标与范围
在开始任何数据处理工作前,必须与业务方对齐目标。明确本次数据处理要解决的核心业务问题(如提升用户留存、优化功能使用率),并界定所需数据的范围(时间跨度、用户群体、行为事件等),避免陷入“为处理而处理”的盲目境地。
步骤2:建立统一的数据接入与收集规范
确保从各个源头(APP、Web、服务器日志、第三方API)接入的数据格式统一、字段定义清晰。制定数据埋点规范文档,明确每个事件的触发时机、上报字段及业务含义,这是后续所有处理工作的基础。
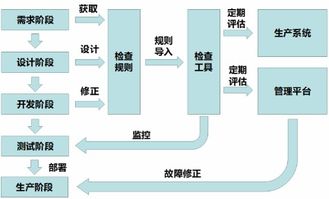
步骤3:构建可靠的数据管道与流处理
设计并实施稳定、低延迟的数据管道。对于实时性要求高的场景(如风控、实时推荐),采用Flink、Spark Streaming等流处理框架;对于批量分析,则可利用Airflow等工具调度定时ETL任务,确保数据能持续、稳定地流向数据仓库或数据湖。
步骤4:实施数据清洗与质量监控
原始数据常包含缺失、异常、重复或格式错误。建立自动化的数据清洗流程,如处理空值、纠正错误格式、剔除明显异常值。建立数据质量监控看板,对数据完整性、准确性、及时性设置阈值告警,做到问题早发现、早修复。
步骤5:进行数据集成与关联
将来自不同业务线、不同系统的数据(如用户行为数据、交易数据、CRM数据)通过唯一的用户ID或其他关键键进行关联与整合,形成统一的用户视图或业务实体视图,打破数据孤岛。
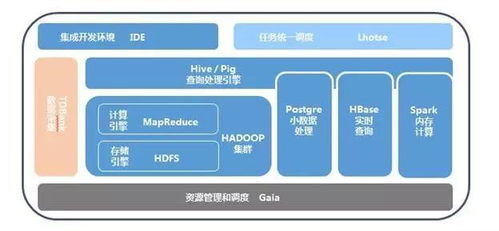
步骤6:设计并开发数据仓库/数据湖分层模型
遵循维度建模或Data Vault等理论,构建清晰的数据分层架构,通常包括:
- ODS(操作数据层):存储原始数据,保持原貌。
- DWD(明细数据层):对ODS层数据进行清洗、整合、规范化后的明细数据。
- DWS(汇总数据层):根据主题域(如用户、商品、渠道)构建的轻度汇总宽表,便于常用分析。
- ADS(应用数据层):为特定业务场景或报表定制的个性化数据聚合结果。
步骤7:定义关键业务指标与数据字典
基于业务目标,明确定义核心指标(如日活跃用户数DAU、转化率、平均订单价值AOV)的计算口径,并形成团队内部公认的数据字典。这是确保整个团队“用同一套语言说话”、避免指标歧义的重中之重。
步骤8:实现数据的自动化加工与调度
将数据清洗、转换、聚合(ETL/ELT)的SQL或代码脚本化、模块化,并利用调度工具(如Airflow, DolphinScheduler)进行自动化、依赖化管理,减少人工干预,保证数据产出的稳定性和可重复性。
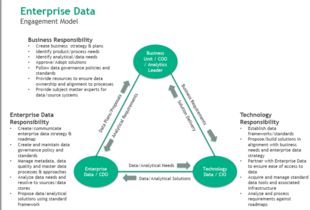
步骤9:建立数据安全与权限管理体系
制定严格的数据安全策略,对敏感数据(如个人信息)进行脱敏或加密处理。依据“最小权限原则”,在数据平台中设置基于角色(RBAC)的细粒度访问控制,确保数据在合规的前提下被安全使用。
步骤10:开发并维护可复用的数据中间层/服务层
针对常用的复杂查询或计算逻辑(如用户分群、生命周期阶段判断),封装成可复用的数据中间表、UDF(用户自定义函数)或微服务API。这能极大提升数据分析师和业务人员的查询效率,并保证计算逻辑的一致性。
步骤11:建立持续优化与问题响应机制
数据处理体系不是一劳永逸的。需要定期评估数据管道的性能、计算资源的消耗、数据产出的时效性。建立有效的问题反馈与响应通道,当业务需求变更或数据异常时,能够快速定位、修复并迭代数据处理流程。
****
数据处理是产品数据运营体系中承上启下的坚实基座。通过以上11个步骤的系统化构建,企业能够将原始、杂乱的数据流,转化为干净、可靠、易用的高质量数据资产,从而为深入的数据分析与精准的业务决策提供强大动力。记住,优秀的数据处理能力,是数据价值得以释放的首要前提。
如若转载,请注明出处:http://www.tobeonetop.com/product/77.html
更新时间:2026-01-12 19:43:53