Cobar 关系型数据的分布式处理系统解析
随着数据量的爆炸式增长,传统单机数据库在处理海量数据时逐渐暴露出性能瓶颈。关系型数据库作为企业核心数据存储的基石,其分布式改造需求日益迫切。Cobar正是在这一背景下应运而生,它是一个基于MySQL协议的关系型数据分布式处理系统,由阿里巴巴开源,旨在解决大规模数据存储与访问的挑战。
一、Cobar的核心架构与设计原理
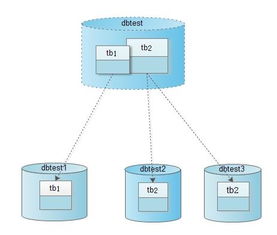
Cobar采用典型的代理模式架构,位于应用层与数据库层之间。其主要组件包括:Cobar Server(代理服务器)、数据节点(DataNode)和MySQL实例。Cobar Server接收应用端的SQL请求,根据预定义的分片规则进行解析、路由和转发,将查询分发到后端多个MySQL实例上执行,最后合并结果返回给客户端。这种架构实现了对应用透明的数据分片(Sharding),使得业务逻辑无需关心底层数据的分布细节。
分片策略是Cobar的核心特性之一。它支持基于范围、哈希或枚举等多种分片算法,允许开发者根据业务特点(如用户ID、时间范围等)灵活定义数据分布规则。例如,可以按用户ID的哈希值将用户表分散到多个数据库,有效避免了单点数据过热的问题。
二、数据处理流程与关键特性
在数据处理方面,Cobar展现了强大的能力:
- SQL解析与路由:Cobar能够解析复杂的SQL语句,识别涉及的分片键,并将查询精准路由到相关分片。对于跨分片的查询(如多表JOIN或全表扫描),Cobar支持将查询分发到所有分片并行执行,再通过结果聚合返回,显著提升了查询效率。
- 事务管理:Cobar支持分布式事务的弱一致性处理。对于单分片事务,它直接委托给底层MySQL的ACID保证;对于跨分片事务,则通过两阶段提交(2PC)协议协调,确保数据的一致性。
- 读写分离与负载均衡:Cobar可以配置主从复制架构,将写操作定向到主库,读操作分摊到多个从库,既提高了系统吞吐量,也增强了可用性。
- 连接池与故障转移:Cobar维护了与后端数据库的连接池,减少了连接开销。当某个MySQL节点故障时,它能自动检测并切换到备用节点,保障服务连续性。
三、Cobar的应用场景与优势
Cobar尤其适用于高并发、大数据量的互联网业务场景,如电商交易、社交网络和日志分析等。其优势主要体现在:
- 水平扩展能力:通过增加数据节点,系统可以线性提升存储容量和处理性能。
- 对应用透明:应用程序几乎无需修改代码,只需调整数据源配置即可接入分布式环境。
- 兼容MySQL生态:完全兼容MySQL协议和语法,现有基于MySQL的工具和驱动可以无缝衔接。
四、挑战与演进
尽管Cobar在分布式处理上表现卓越,但也面临一些挑战。例如,跨分片事务的性能开销较大,复杂查询的优化仍有提升空间。随着技术的发展,Cobar的后续演进版本(如MyCat等)在分布式事务优化、弹性扩缩容等方面做了进一步改进。
Cobar作为早期开源的关系型数据分布式处理系统,为业界提供了重要的架构参考。它通过智能的数据分片和透明的代理机制,有效解决了关系型数据库的扩展性问题,至今仍在许多企业系统中发挥着关键作用。对于寻求数据库水平扩展的团队而言,理解Cobar的设计思想与实践经验,依然是构建高性能分布式数据平台的重要基础。
如若转载,请注明出处:http://www.tobeonetop.com/product/82.html
更新时间:2026-06-18 07:21:28