面向多星多任务的大数据处理系统设计
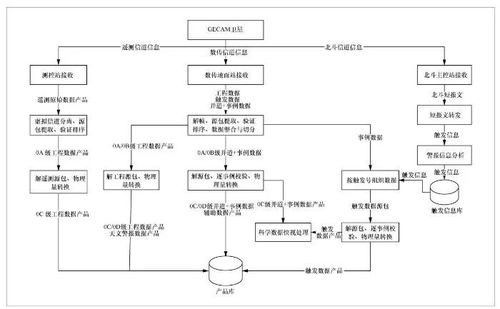
随着航天技术的飞速发展,全球在轨卫星数量急剧增加,遥感观测、气象监测、通信导航等各类航天任务产生了海量、多源、异构的观测数据。如何高效、可靠地处理这些来自多颗卫星、服务于多类任务的海量数据,已成为航天测控、遥感应用等领域面临的核心挑战。构建一个面向多星多任务的大数据处理系统,是实现数据价值最大化、提升任务响应能力的关键。
一、 系统设计的核心挑战
- 数据海量与异构性:多颗卫星(如光学、雷达、高光谱、气象卫星)产生的数据格式、分辨率、时相各不相同,数据体量呈指数级增长,传统处理架构难以应对。
- 任务多样性与实时性要求:系统需同时支撑科学研究、灾害应急、国防安全、商业服务等不同任务,其对数据处理的时效性、精度和产品类型要求各异。
- 资源动态调度与协同:计算、存储、网络资源需要在多个并发任务间高效、弹性地分配,确保高优先级任务(如灾害应急)能得到即时保障。
- 系统可靠性与可扩展性:需满足7x24小时不间断运行,并能平滑扩展以容纳未来新的卫星、传感器和任务需求。
二、 系统总体架构设计
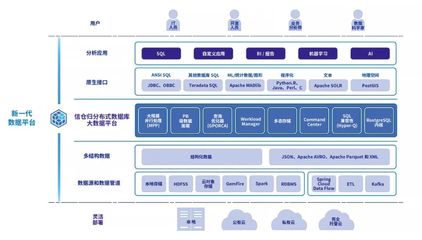
一个典型的面向多星多任务的大数据处理系统通常采用分层、微服务化的云原生架构,以实现松耦合、高内聚和弹性伸缩。
1. 数据接入与管理层
- 多源接入:通过地面站网、数据中继卫星等渠道,接收来自不同卫星的原始数据流。
- 统一编目与存储:对原始数据、中间数据和最终产品进行标准化描述与元数据管理,并利用分布式对象存储(如HDFS、Ceph)或云存储服务进行持久化,形成数据湖。
2. 分布式计算处理层(核心)
- 计算框架:采用批流融合的大数据计算框架,如Apache Spark(批处理)、Apache Flink(流处理),以应对历史数据回溯分析和实时数据流处理。
- 任务调度与编排:引入Kubernetes等容器编排工具,配合自定义的任务调度器。调度器能根据任务类型(CPU密集型如正射校正、GPU密集型如目标识别)、优先级、数据局部性和资源状态,动态地将处理任务分解并调度到计算集群的各个节点上。
- 算法容器化:将辐射定标、大气校正、图像融合、信息提取等各类处理算法封装为独立的Docker容器,实现算法的解耦、复用和敏捷部署。
3. 智能服务与协同层
- 服务化接口:通过RESTful API或消息队列,向上层应用(如WebGIS平台、移动应用、专业分析工具)提供标准化的数据查询、订阅、处理任务提交和产品获取服务。
- 工作流引擎:对于复杂的多步骤处理任务(如“数据获取->预处理->变化检测->报告生成”),采用工作流引擎(如Apache Airflow)进行可视化编排与自动化执行。
- 数据与知识协同:引入数据仓库或知识图谱技术,对多源数据进行关联、融合与深度挖掘,形成更高层次的态势信息和知识,支撑智能决策。
4. 资源监控与运维层
- 全景监控:对集群的CPU、内存、存储、网络IO以及各类任务的状态、进度、性能进行实时监控与可视化。
- 弹性伸缩:基于监控指标和任务队列负载,自动触发计算资源的扩缩容,实现成本与效率的最优平衡。
三、 关键技术与创新点
- 异构计算资源统一池化:整合CPU、GPU、FPGA等异构计算资源,通过虚拟化或容器化技术形成统一资源池,使不同类型的数据处理任务能调度到最适合的硬件上执行。
- 基于优先级和公平性的动态调度策略:设计混合调度策略,既保证灾害应急等高优先级任务的即时抢占式处理,又通过队列、权重等机制保障科研等长周期任务的公平性与进展。
- 存算分离与数据本地化优化:采用存算分离架构提升系统弹性,同时通过智能缓存、数据预取和计算任务调度至数据所在节点附近,最大限度减少数据网络传输开销。
- AI赋能的数据智能处理:集成机器学习、深度学习框架(如TensorFlow, PyTorch),将AI模型用于数据质量自动控制、智能压缩、特征自动提取与分类、异常检测等环节,提升处理的自动化与智能化水平。
四、 与展望
面向多星多任务的大数据处理系统,其核心思想是以数据为中心,以服务为导向,以智能为驱动。通过构建云原生、微服务化的弹性架构,并深度融合大数据与人工智能技术,该系统能够有效应对数据洪流,灵活服务多元任务,最终将海量卫星数据高效转化为精准、及时、可用的信息和知识。
随着星上计算、边缘计算技术的发展,数据处理将进一步向“星-地-云”协同的泛在计算模式演进。区块链等技术可能在数据确权、交易与安全共享方面为系统带来新的维度。系统设计需保持前瞻性和开放性,以持续适应航天大数据领域日新月异的发展需求。
如若转载,请注明出处:http://www.tobeonetop.com/product/81.html
更新时间:2026-06-18 18:06:04